
案例分析练习:
FIFA2018球员数据分析
一、首先要明确分析的目标
当获取一份数据集时,应该对数据信息做个总体的了解。
1、加载数据文件
2、简单查看下数据,有哪些列,都是什么类型的值
head方法默认显示头部的5行
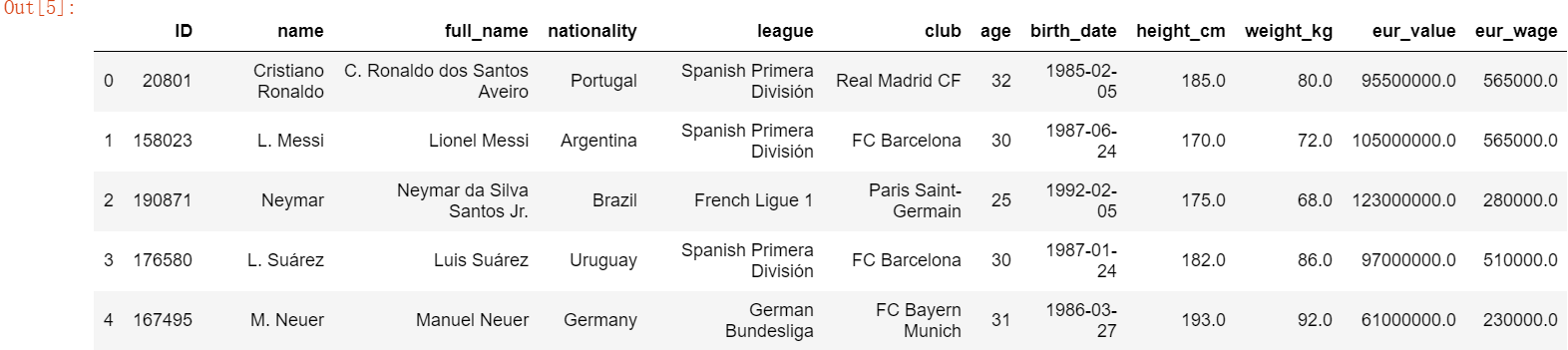
数据字段信息
3、看下数据整体统计信息,了解下数据总体分布。
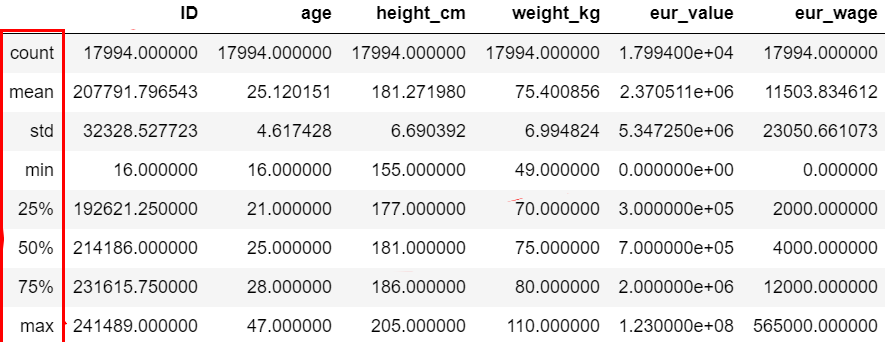
二、对数据进行预处理
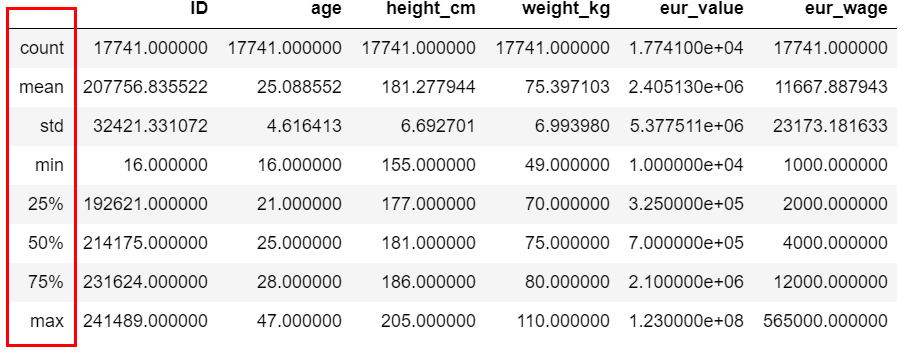
所有需要分析的数据都需要查看,对于数值型,可以看describe⽅法输出的信息,重点关注最⼤值、最⼩值、平均值、行数等数据。
1、对需要分析的字段依次查看是否有null值
执行显示:name没有null值
执行显示:full_name没有null值
执行显示:nationality没有null值
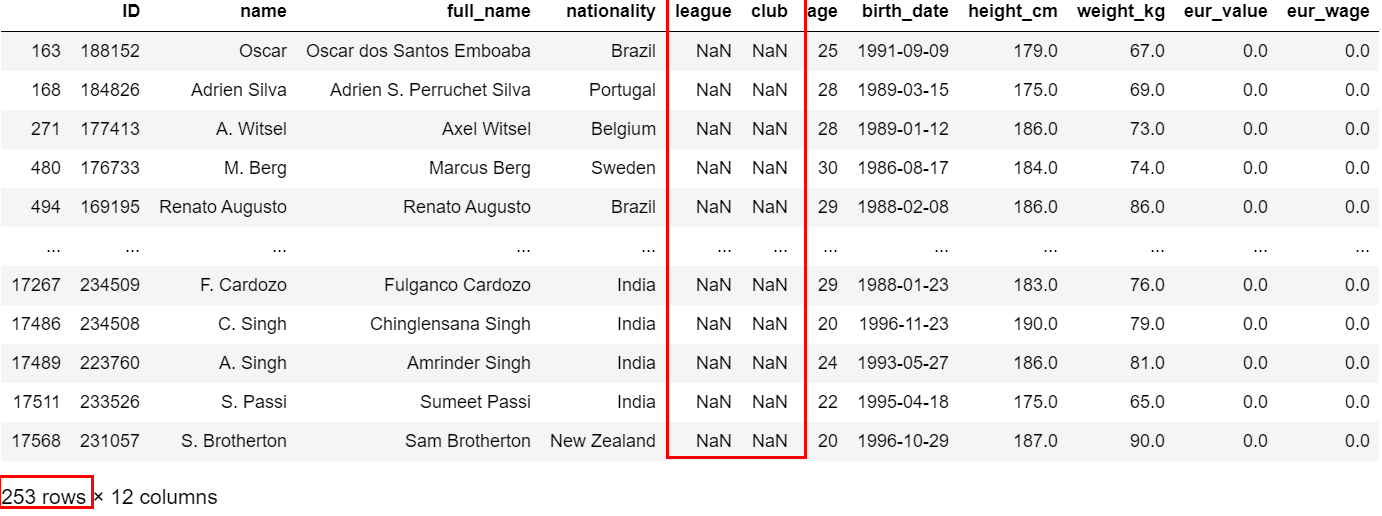
执行显示:league有253条null值数据,需要进行处理
所在联赛、俱乐部都没有值,身价和周薪也是0,253条数据对于一万多条数据来说影响还好,可以删除。
删除数据一般放在后面进行,这里因为其他列数据也是异常,所以可以先删掉
2、使用drop方法删除league空值数据
检查一下是否已删除成功
在查看下club是否还有空值
3、如果觉得age最小值有问题,单独输出来看下;其他列处理方法类似。
4、 eur_value为0的列可以使用平均值来填充(只有几条数据,也可以删除)
查看eur_value为0的列是否填充成功

eur_wage列最⼩值也是0,也需要检查下
5、最后看下有⽆重复值(如果有可以⽤drop_duplicates处理)
指定列判断是否有重复值
也可以单独查看full_name是否有重复值
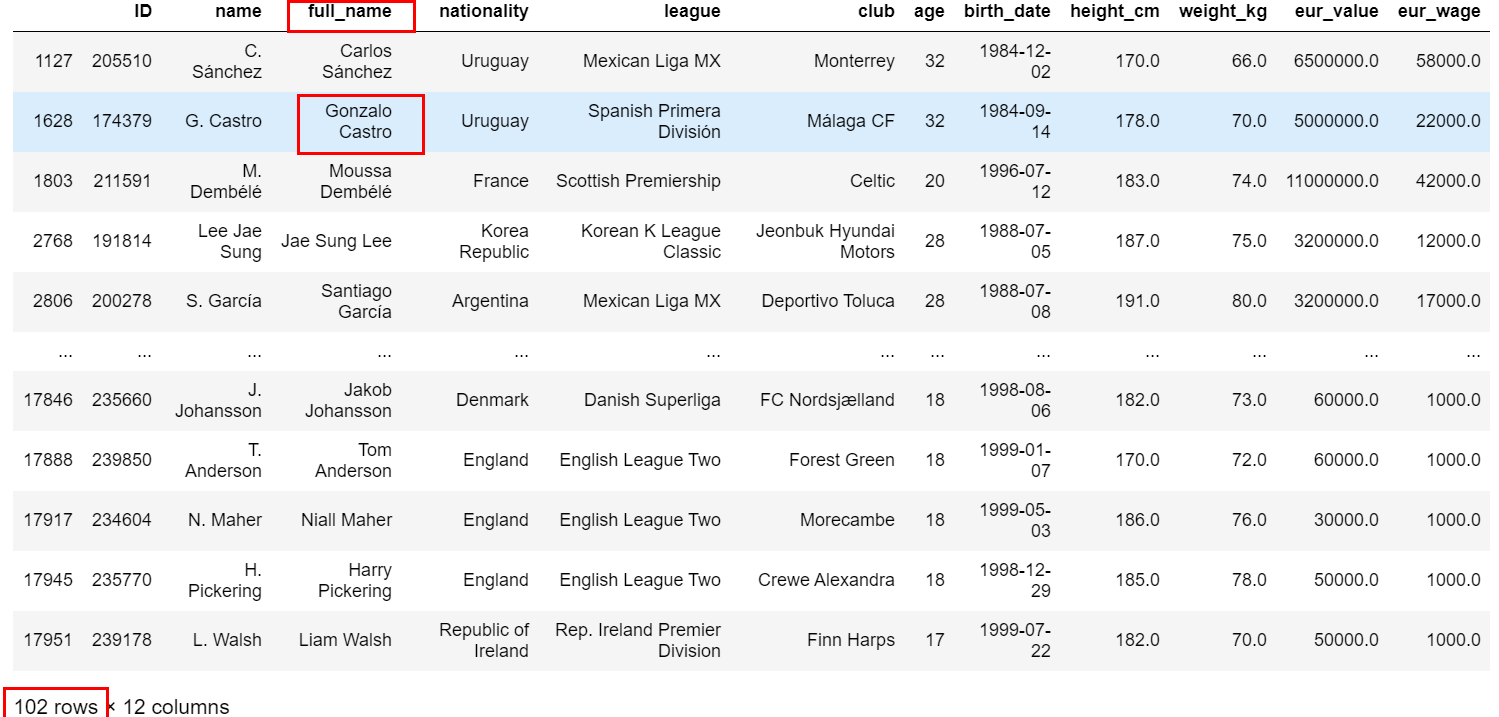
随便找条full_name重复的记录看下
数据清洗完毕,开始分析
三、确定分析维度和指标
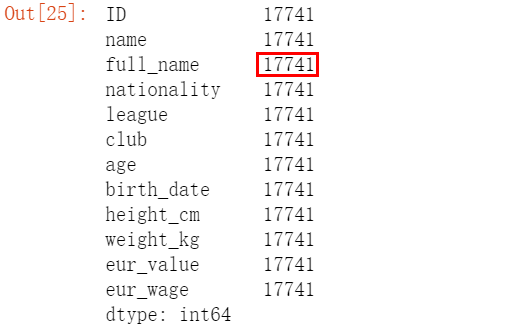
1、查看数据样本总数
2、对于数值类型列的⼀些常⻅的统计学指标,使用describe方法查看
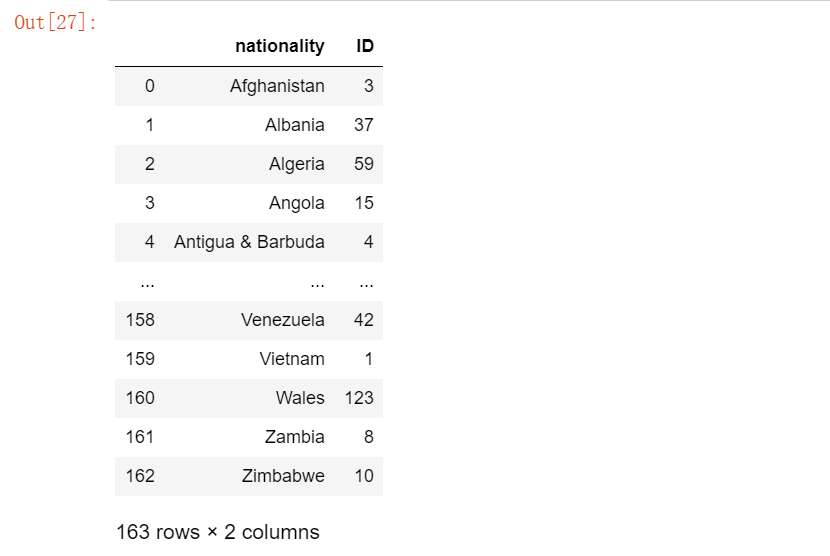
3、对于离散类型数据,直接使用groupby分组,如:国家、俱乐部等维度
将ID列重命名为player_count
使用sort_values()函数按照运动员数量进行排序
pandas中的sort_values()函数原理类似于SQL中的order by,可以将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序。
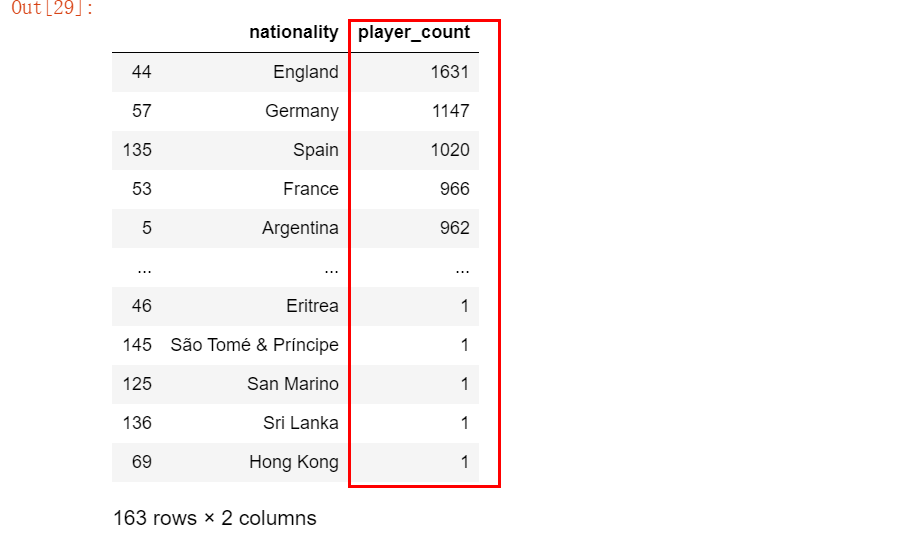
运动员数量⼤于100的国家列表
使用league列进行分组统计各⼤联赛得运动员数量
求各俱乐部平均周薪
使用groupby先对club进行分组,再用mean()方法求得英超联赛English Premier League各个俱乐部球员的平均⽉薪,然后排序sort_values()
4、对于连续型数据,通常使用分区间的方式;如:年龄、时间等维度,使用pd.cut()方法分区间进行统计。
使用numpy的arange()函数生成等差的数组用于分段统计
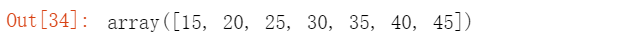
使用cut()将数据进行分区间

以年龄的维度,对已分出区间的数据进行groupby分组统计。

四、可视化展示
简单的折线图展示:
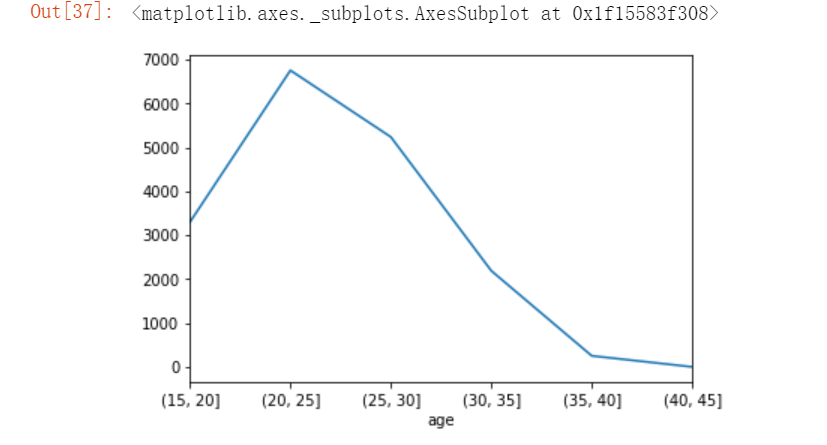
为了使图标展示更好看处理index

柱状图展示:
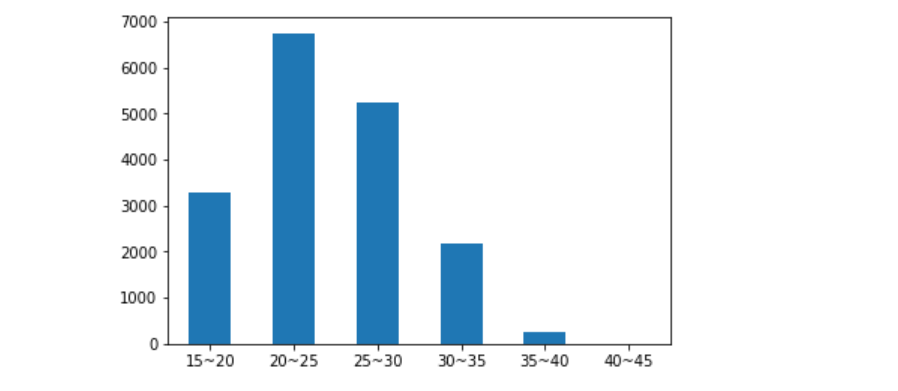
函数生成等差的数组用于分段统计")
函数生成等差的数组用于分段统计")





























